Graph Databases
What is a Graph Database?
A graph database is a specialized database platform designed specifically for storing and manipulating graphs. Graphs are made up of vertices, edges, and properties, which together can represent many different forms of data. Due to the various shapes and sizes of graphs, most graph databases are implemented using NoSQL, which means they are not using a traditional relational database model. In fact, a major benefit of not being forced into a structured relational model is that there have become two leading methods for storing and representing graph databases, the property graph model and resource description framework (RDF) model. These two methods are both very popular among industry leading graph database technologies, proving they both can be viable when used to represent graph data structures.
Property Graph Model
Property graphs model graphs as a set of nodes and relationships, where either nodes or relationships can have additional attributes, called properties. This way of representing a set of vertices and edges is straightforward, as it adheres closely to the visual representation of a traditional graph. In memory, a property graph is usually stored using some adaptation of a linked data structure, such that nodes and relationships contain pointers to each other.
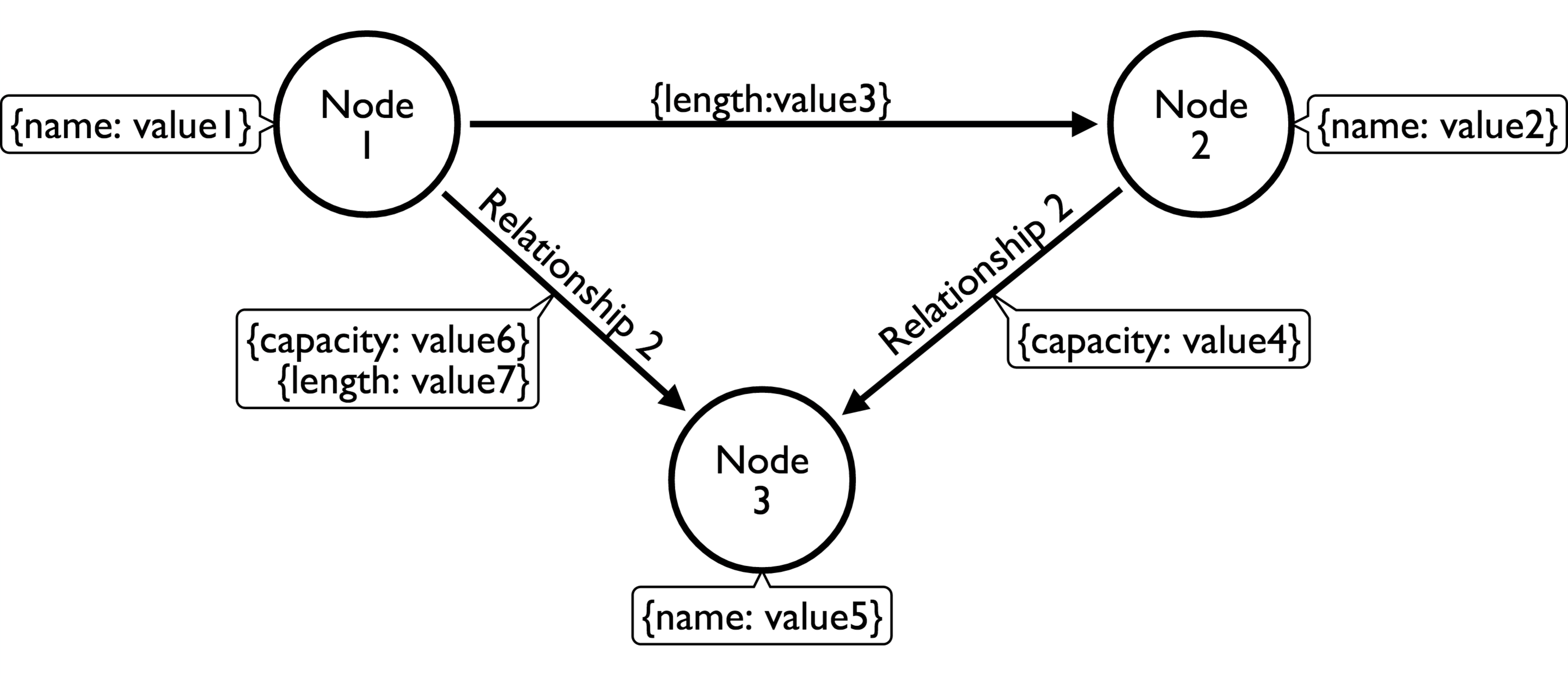
Resource Description Framework Model
The RDF model is a bit more difficult to grasp than the property graph model. RDF is a method of representing highly interconnected data. Therefore, it can easily be applied to graph databases. In the RDF model, data is stored in triples: subject, predicate, and object. This is very similar to a node and a relationship in the property graph model. As triples are created, a network of subjects, predicates, and objects is formed. This network looks exactly like a graph, with vertices made up of subjects and objects and predicates as edges. The biggest difference between the property graph model and the RDF model is that the unique identifier in an RDF model is the triple, whereas in the property graph model, nodes and relationships can be uniquely identified individually.
Popular Graph Databases
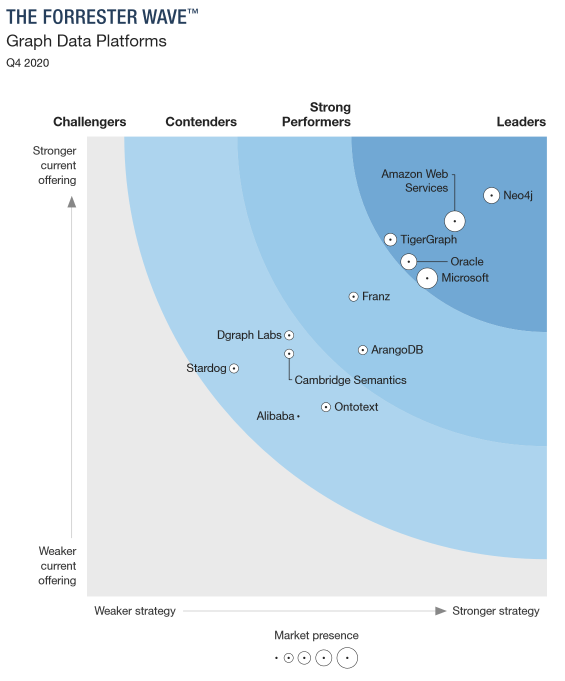
The market for graph databases is large, and there exist many different companies and open source projects that have developed different graph database products. In order for my adaptation of a graph database with Bundled References to be relevant, it must adapt an already common graph database product. To find the currently most used graph databases, I consulted a market research report conducted by Forrester Research. This report indicated that Neo4j and Amazon Web Services (Amazon Neptune) are the industry leaders, which is unique in the fact that they use opposite graph models. Neo4j is an open source project utilizing the property graph model, whereas Amazon Neptune is a proprietary graph database implemented using the RDF model. To learn more, I investigated both of these technologies.
Amazon Neptune
Amazon Neptune is a fully managed graph database service designed specifically for highly connected graph datasets. It is implemented using a derivative of the RDF model, in which instead of using triples to identify data, it uses a quad: subject, predicate, object, and graph. It functions the same way as the RDF model, where a network of these quads develops into a graph. However, the fourth graph element provides additional metadata that Amazon Neptune uses for named graph identifiers, which add support for multiple graphs. Amazon Neptune has also added support for popular query language Gremlin, which is used for querying.
The major problem I encountered with Amazon Neptune was that it is proprietary. This means that if I am looking to add additional functionality using Bundled References, I would have to add on to the service as a third party instead of being able to integrate directly. Therefore, although this is an industry leader in graph databases, it does not fit into the scope of this project.
Neo4j
Neo4j is an open source native graph database using the property graph model. Because it is open source, its exact implementation is public. In fact, I was able to utilize a textbook called Graph Databases, which describes in depth the storage model of Neo4j.
In memory, Neo4j stores nodes, relationships, and properties using linked lists. Each of these object types are stored separately as a fixed size object. Nodes contain pointers to the head of their relationship list and the head of their property list. The property list acts as a singly linked list where each property points to the next property in the list. The relationship list is where most of the querying for Neo4j is implemented. Therefore, each relationship in the relationship list has a pointer to the source node and destination node for itself, the previous relationship in the list, and the next relationship in the list. This allows for queries to only need to traverse the relationship list in order to find both nodes and relationships.
Due to the reliance on linked data structures for the implementation of Neo4j and the fact that it is open source, it seems like the optimal graph database to add Bundled References to. In fact, because the code base is available on GitHub, I have the ability to implement Bundled References directly into the linked lists themselves. Therefore, this project will add Bundled Reference functionality to Neo4j in order to increase its performance with aggregate and range queries.